-
Создана пользователем
 Ярослав Воробьев. Последнее обновление: 07 февр., 2023
Время чтения: 2 мин.
Ярослав Воробьев. Последнее обновление: 07 февр., 2023
Время чтения: 2 мин.
В данной статье мы разберем, что за окно появляется после обучения агента NLU, и какая информация в нем выводится.
Не пугайтесь при появлении данного окна - это не сообщение об ошибке.
Пример сообщения
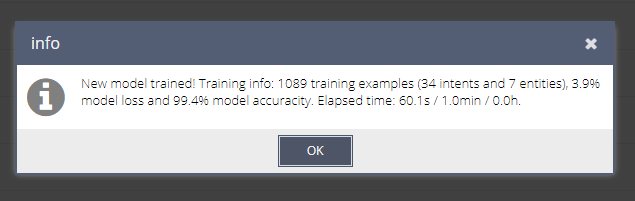
Выводимая информация
- New model trained! - Сообщение о том, что была обучена новая модель.
- Training info: - Информация о том, как прошло обучение модели.
- X training examples - Количество фраз, внесенных в сущности и намерения агента. Системные намерения и сущности не учитываются.
- X intents - Количество намерений в агенте.
- X entities - Количество сущностей в агенте.
- X% model loss - потери модели. Чем ниже - тем лучше. При высоких значениях (близких к 10% и выше) может означать, что в данных присутствует много пересечений - например, схожие фразы могут относиться к разным намерениям - из-за этого может повышаться значение потерь модели.
- X% model accuracy - точность модели. Чем выше - тем лучше. Определяется на основе тестовой выборки - из каждого намерения берется случайная выборка фраз, примерно 5% от количества фраз в каждом намерении (но не менее одной фразы), из-за этого рекомендуется вносить не менее 30 фраз в каждое намерение, и чем их больше, тем лучше. Далее агент прогоняет эту тестовую выборку, и, допустим, если удалось корректно распределить 90 из 100 фраз тестовой выборки в намерения - точность будет 90%.
- Elapsed time: X s / Y min / Z h - Время потраченное на обучение агента в секундах, минутах, и часах. Время обучения зависит от количества фраз, сущностей и намерений - чем их больше, тем дольше будет идти обучение. Например, базовый агент, содержащий ~1000 фраз, обучается за одну-две минуты.
Снижение потерь модели (model loss)
При высоких значениях потерь модели (10% и выше) стоит проверить набор фраз в разных намерениях на наличие схожих фраз. Например, если в разные намерения внесены фразы «привет, как дела?» и «привет как попасть в метро» - будет расти значение потерь, так как эти фразы схожи.
Если при тестах фраза попадает в два намерения с достаточно близкой друг к другу точностью распознавания, стоит проверить набор фраз на пересекающиеся фразы.
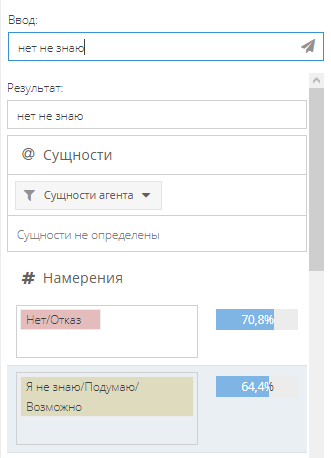
Повышение точности модели (model accuracy)
При низкой точности модели (90% и ниже) стоит проверить набор данных - это может означать, что недостаточно данных для обучения, и стоит наполнить агента большим количеством фраз - в каждом намерении должно быть не менее 30 различных фраз.