...
Пример сообщения
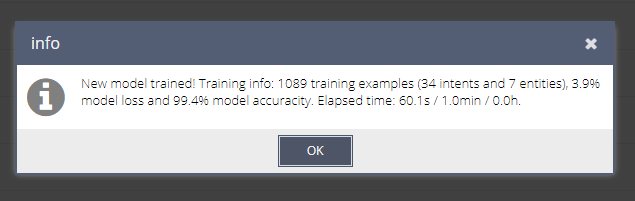
Выводимая информация
| Поле | Значение |
|---|---|
| New model trained! |
...
| Сообщение о том, что была обучена новая модель. | |
| Training info: |
...
| Информация о том, как прошло обучение модели. | |
|
...
| Количество фраз, внесенных в сущности и намерения агента. Системные намерения и сущности не учитываются. | |
|
...
| Количество намерений в агенте. | |
|
...
| Количество сущностей в агенте. | |
|
...
Потери модели. Чем ниже - тем лучше. | |
|
...
Точность модели. Чем выше - тем лучше. | |
| Elapsed time: X s / Y min / Z h |
...
| Время потраченное на обучение агента в секундах, минутах, и часах. Время обучения зависит от количества фраз, сущностей и намерений - чем их больше, тем дольше будет идти обучение. Например, базовый агент, содержащий ~1000 фраз, обучается за одну-две минуты. |
Снижение потерь модели (model loss)
...